前言
Google研发的V8 JavaScript引擎性能优异。我们请熟悉内部程序实现的作者依源代码来看看V8是如何加速的。
作者:Community Engine公司研发部研发工程师Hajime Morita
Google的Chrome中的V8 JavaScript引擎,由于性能良好吸引了相当的注目。它是Google特别为了Chrome可以高速运行网页应用(WebApp)而开发的。Chrome利用Apple领导的WebKit研发计划作为渲染引擎(Rendering engine)。 WebKit也被用在Safari浏览器中。WebKit的标准配备有称为JavaScriptCore的JavaScript引擎,但Chrome则以V8取代之。
V8开发小组是一群程序语言专家。核心工程师Lars Bak之前研发了HotSpot,这是用在Sun Microsystems公司开发的Java虚拟机器(VM)之加速技术。他也在美国的Animorphic Systems公司(于1997年被Sun Microsystems所并购)研发了称为Strongtalk的实验Smalltalk系统。V8充分发挥了研发HotSpot和Strongtalk时所获得的知识。

图1 开发自己的JavaScript引擎
Apple的Safari和Google的Chrome使用相同的渲染引擎。配有JavaScriptCore的WebKit渲染引擎在JavaScript引擎中是标准配备,但在Chrome却被V8取代了.
高速引擎的需求
Google研发小组在2006年开始研发V8,部分的原因是Google对既有JavaScript引擎的执行速度不满意。我认为当时JavaScript引擎很慢是有两个原因的:开发的历史背景,以及JavaScript语言的复杂性。
JavaScript存在至少10年了。在1995年,它出现在网景(Netscape Communications)公司所研发的网页浏览器Netscape Navigator 2.0中。然而有段时间人们对于性能的要求不高,因为它只用在网页上少数的动画、交互操作或其它类似的动作上。(最明确的是为了减少网络传输,以提高效率和改善交互性!)浏览器的显示速度视网络传输速度以及渲染引擎(rendering engine)解析HTML、风格样式表(cascading style sheets, CSS)及其他代码的速度而定。浏览器的开发工作优先提升渲染引擎的速度,而JavaScript的处理速度不是太重要。同时出现的Java有相当大的进步,它被做得愈来愈快,以便和C++竞争。
然而,在过去几年,JavaScript突然受到广泛使用。原因是之前被当成桌面应用的软件(其中包括Office套件等),现已成为可以在浏览器中执行的软件。
Google本身就推出了好几款JavaScript网络应用,其中包括它的Gmail电子邮件服务、Google Maps地图数据服务、以及Google Docs office套件。
这些应用表现出的速度不仅受到服务器、网络、渲染引擎以及其他诸多因素的影响,同时也受到JavaScript本身执行速度的影响。然而既有的JavaScript引擎无法满足新的需求,而性能不佳一直是网络应用开发者最关心的。
语言本身的问题
JavaScript语言的规范现在性能压力巨大。例如,这在当它判定变量类型时就相当显而易见。如C++和Java等主流语言采用静态类型(static typing)。当代码编译时,就可宣告变量类型。由于不需要在执行期间检查数据类型,因此静态类型占有性能上的优势。
在例如C++和Java等一般处理系统中,fields*和methods*等的内容是以数组储存,以1:1位移(offset)对应fields和methods等的名称(图2)。个别变量和methods等储存的位置,是针对各个类定义的。在C++和Java等语言中,已事先知道所存取的变量(类)类型,所以语言解释系统(Interpreting system)只要利用数组和位移来存取field和method等。位移使它只要几个机器语言指令,就可以存取field、找出field或执行其他任务。
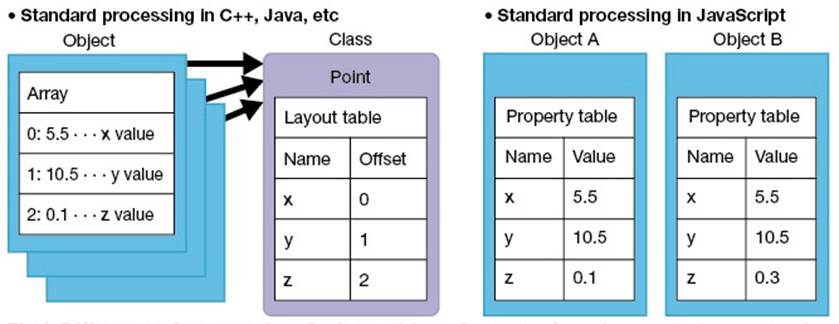
图2 JavaScript和C++、Java的不同
C++、Java及其他处理系统将fields和methods等,以它们的名称以1:1对应数组内的位移值储存在数组中。会事先知道要存取的变量类型(类),因此可以只用数组和位移就可以存取fields和methods等。然而在JavaScript,个别的对象都有自己属性和方法等的表格。每一次程序存取属性或是呼叫方法时,都必须检查对象的类型并执行适当的处理。
- Field:属对象的变量。C++中称为成员变量。
- Method:属对象的处理类型。C++中称为成员函式。
- Property属性:JavaScript属性是对象自己拥有的变量。在JavaScript中,属性中不只可以是标准的值,也可以是methods。
- Hash table哈希表:一种数据结构会传回与特定关键相关之对应值。它有一个内部数组,使用键值(key)所产生之Hash值作为数组中特定位置清单值的位移。如果刚好在相同的位置上产生不同关键之Hash值时,清单位置会储存多个值,这意味着在传回任何值之前必须先检查Hash值是否符合。
而另外一方面,JavaScript则是利用动态类型(dynamic typing)。 JavaScript变量没有类型,而所指定对象的类型在第一次执行时(换言之,动态地)就已判定了。每次在JavaScript中存取属性(property),或是寻求方法等,必须检查对象的类型,并照着进行处理。
许多JavaScript引擎都使用哈希表(hash table)来存取属性和寻找方法等。换言之,每次存取属性或是寻找方法时,就会使用字符串作为寻找对象哈希表的键(key)(图3)。
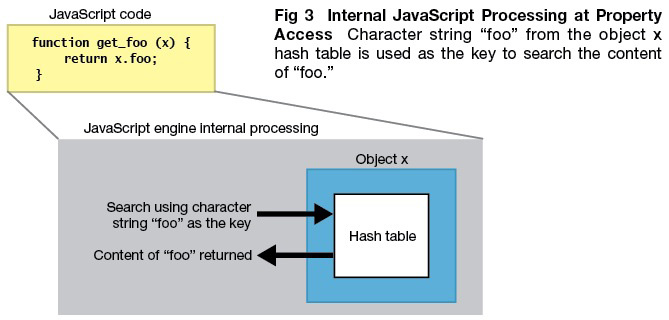
图3 属性存取时的内部JavaScript处理
使用对象x哈希表的字符串「foo」作为搜寻「foo」内容的关键字。
搜寻哈希表是一个连续动作,包含从散列(hashing)值中判定数组内位置,然后查看该位置的键值(key)是否符相等。然后可以使用位移直接读取数据的数组比较起来,利用此方法存取较费时。
使用动态类型的其他语言,还有Smalltalk和Ruby等。这些语言基本上也是搜寻哈希表,但它们利用类来缩短搜寻时间。然而,JavaScript没有类。除了「Numbers」指示数字值、「Strings」为字符串以及其他少数几种类型外,其他对象都是「Object」型。程序员无法宣告类型(类),因此无法使用明确的类型来加速处理。
JavaScript的弹性允许在任何时间,在对象上新增或是删除属性和方法等(请参阅附录)。JavaScript语言非常动态,而业界的一般看法是动态语言比C++或Java等静态语言更难加速。尽管有困难,但V8利用好几项技术来达到加速的目的:
1. JIT编译 (JIT Compile)
不用字节码(bytecode)生成机器语言
从性能的角度来看,V8具有4个主要特性。首先,它在执行时以称为及时(just-in-time, JIT)的编译方法,来产生机器语言。这是个普遍用来改善解释速度的方法,在Java和.NET等语言中也可以发现此方法。V8比Firefox中的SpiderMonkey JavaScript引擎,或Safari的JavaScriptCore等竞争引擎还要早的实践了这一技术。
V8 JIT编译器在产生机器语言时,不会产生中间码(图4)。例如,在Java编译器先将原始码转换成一个以虚拟中间语言(称为字节码,bytecode)表示的一类文件 (class file)。Java编译器和字节码编译器产生字节码,而非机器语言。Java VM按顺序地在执行中解释字节码。此执行模式称为字节码解释器(bytecode interpreter)。 Firefox的SpiderMonkey具有一个内部的字节码编译器和字节解释器,将JavaScript原始码转换成它自家特色的字节代码,以便执行。
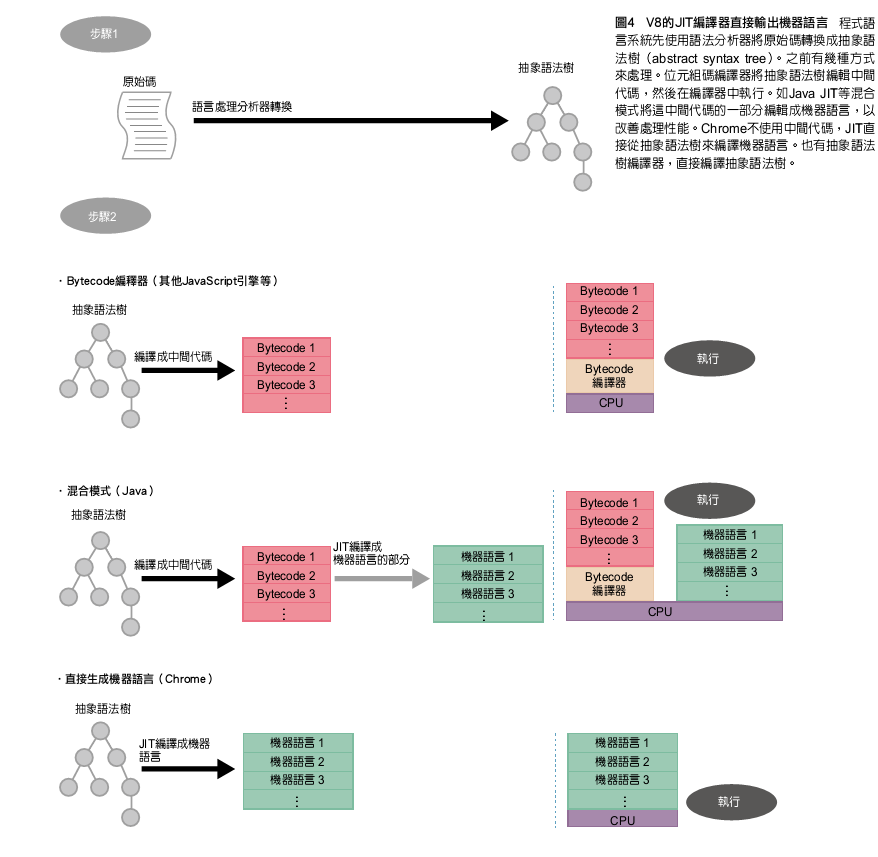
图4 V8的JIT编译器直接输出机器语言
序语言系统先使用语法分析器将原始码转换成抽象语法树(abstract syntax tree, AST)。之前有几种方式来处理。字节码编译器将抽象语法树编译为中间代码,然后在编译器中执行。如Java JIT等混合模式将这中间代码的一部分编译成机器语言,以改善处理性能。Chrome不使用中间代码,JIT直接从抽象语法树来编译机器语言。也有抽象语法树解释器,直接解析抽象语法树。
事实上,Java VM目前使用一个以HotSpot为基础的JIT编译器。它扮演字节码解释器的角色,来解析代码,将常执行的代码区块转换成机器语言然后执行,这就是混合模式(hybrid model)。
字节码解释器、混合模式等等,具有制作简单且有绝佳可移植性的优点。只要是引擎可以编译的原始码,那么就可以在任何CPU架构上执行字节码,这正是为什么该技术被称为「虚拟机(VM)」的原因。即使在产生机器代码的混合模式中,可以借由编写字节码的解释器开始进行开发,然后实现机器语言生成器。通过使用简单的位元码,在机器代码产生时,要将输出最佳化就变得容易许多。
V8不是将原始程序转换成中间语言,而是将抽象语法直接产生机器语言并加以执行。没有虚拟机,且因为不需要中间表示式,程序处理会更早开始了。然而,另一方面,它也丧失了虚拟机的好处,例如透过字节码解释器和混合模式等,所带来的高可移植性(portability)和优化的简易性等。
2. 垃圾回收管理
Java标准特性的精妙实现
第二个关键的特性是,V8将垃圾回收管理(garbage collection, GC*)实作为「精确的GC*」。相反的,大部分的JavaScript引擎、Ruby及其他语言编译器都是使用保守的GC*(conservative GC),因为保守的GC实作简单许多。虽然精确的GC更为复杂,但也有性能上的优点。Oracle(Sun)的Java VM就是使用精确GC。
- Garbage collection(GC)垃圾回收管理:自动侦测被程序保留但已不再使用的存储器空间并释放。
- 保守(conservative) GC:没有分别严格管理指标器和数字值之存储器回收管理。此方法是如果它可以成为指标,那就以指标来看待它,即使它可能个数值。此方法防止对象被意外回收,但它也无法释出可能的存储器。
虽然精确GC本身就是高效率的,但以精确GC为基础的高级算法,如分代(Generational) GC、复制(copy) GC以及标记和精简处理(mark-and-compact processing)等在性能上有明显的改善。分代(Generational) GC藉由分开管理「年青分代(Young Generational)」对象(经常收集)和「旧分代(Old Generational)」对象(相对长寿的对象)而提升了GC效率。
V8使用了分代(Generational)GC,在新分代(Generational)处理上使用轻度(light-load)复制GC,而在旧GC上使用标记和精简GC,因为它须在内存空间内移动对象。这很难在保守GC中执行。在对象的复制中,压缩(compaction)(在硬盘方面称为defrag)和类似动作时,对象的地址会改变,且基于这个原因,最普遍的方法是用「句柄」(handles)间接地引用地址。然而,V8不使用句柄(handles),而是重写该对象引用的所有数据。不使用句柄(handles)会使实现更困难,但却能改善性能因为少了间接引用。Java VM HotSpot也使用相同的技术。
3. 内嵌缓存(inline cache)
JavaScript中不可用?
V8目前可以针对x86和ARM架构产生适合的机器语言。虽然没采用C++或Java中传统的优化方式,V8还是有动态语言与生俱来的速度。
其中一项良好范例是内嵌缓存(inline cache),这项技巧可以避免方法呼叫和属性存取时的哈希表搜寻。它可以立即缓存之前的搜寻结果,因此称为「内嵌」。人们知道此技术已有一段时间了,已经被应用在Smalltalk、Java和Ruby等语言中。
内嵌缓存假设对象都有类型之分,但在JavaScript语言中却没有。直到V8出现后,而这就是为什么以前的JavaScript引擎都没有内嵌缓存的原因。
为了突破此限制,V8在执行时就分析程序操作,并利用「隐藏类」(hidden classes)为对象指定暂时的类。有了隐藏类,即使是JavaScript也可以使用内嵌缓存。但是这些类是提升执行速度之技巧,不是语言规范的延伸。所以它们无法在JavaScript代码中引用。
4. 隐藏类
储存类型转换信息
隐藏类为没有类之分的JavaScript语言规范带来有趣的挑战,同时也是V8用来提升速度最独特的技巧。它们值得更深入的探究。
在V8中建立类有两个主要的理由,即(1)将属性名称相同的对象归类,及(2)识别属性名称不同的对象。前一类中的对象有完全相同的对象描述,而这可以加速属性存取。
在V8,符合归类条件的类会配置在各种JavaScript对象上。对象引用所配置的类(图5)。然而这些类只存在于V8作为方便之用,所以它们是「隐藏」的。
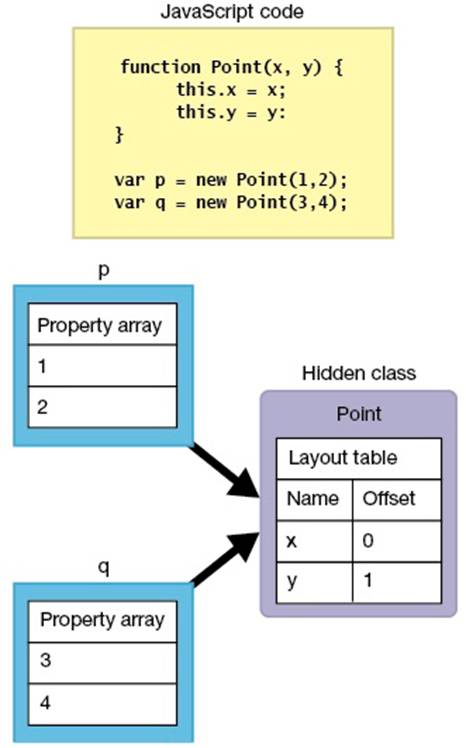
图5 V8对象有隐藏类的引用
如果对象的描述是相同的,那么隐藏类也会相同。在此范例中,对象p和q都属于相同的隐藏类
我上面提到随时可以在JavaScript中新增或删除属性。然而当此事发生时会毁坏归类条件(归纳名称相同的属性)。V8借由建立属性变化所需的新类来解决。属性改变的对象透过一个称为「类型转换(class transition)」的程序纳入新级别中。
第二个目标-识别属性名称不同的对象-则是借由建立新类来达成。然而,如果每一次属性改变就建立一个新类的话,那就无法持续达到第一个目标了(归纳名称相同的属性)。
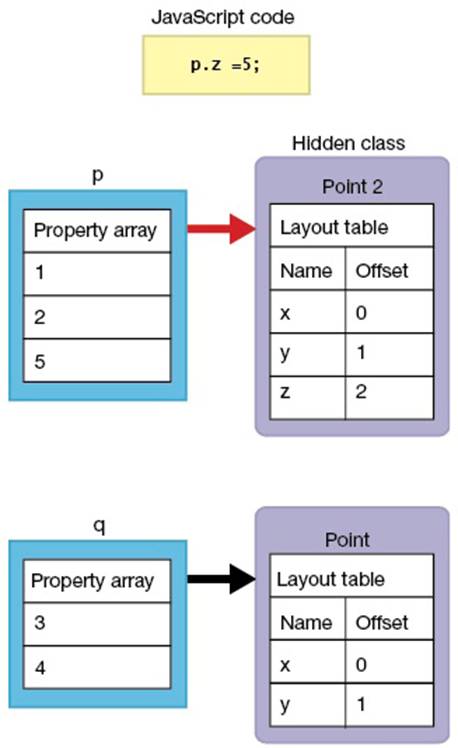
图6 配置新类:类型转换
属性改变的对象会被归为新类。当对象p增加了新属性z时,对象p就会被归为新类。
V8将变换信息储存在类内,来解决此问题。考量图7,它说明了图6中所示的情形,当隐藏类Point有x和y属性时,新属性x就会新增至Point级的对象p中。当新属性z加到对象p时,V8会将「新增属性p,建立Point2类」的信息储存在Point级的内部表格中(图7,步骤1)。

图7 在类中储存类变换信息当在对象p中加入新属性z时,V8会在Point类内的表格上记录「加入属性z,建立类Point2」(步骤1)。当同一Point类的对象q加入属性z时,V8会先搜寻Point类表。如果它发现了Point2类已加入属性z时,就会将对象q设定在Point2类(步骤2)。
当新属性z新增至也是Point级的对象q时,V8会先搜寻Point级的表格,并发现Point2级已加入属性z。在表格中找到类时,对象q就会被设定至该类(Point2),而不建立新类(图7,步骤2)。这就达到了归纳属性名称相同的对象之目的。
然而此方法,意味着与隐藏类对应的空对象会有庞大的转换表格。V8透过为各个建构函数建立隐藏类来处理。如果建构函数不同,就算对象的陈述(layout)完全相同,也会为它建立一个新的隐藏类。
内嵌缓存
其它的JavaScript引擎和V8不同,它们将对象属性储存在哈希表中,但V8则将它们储存在数组中。位移信息-指定个别属性在数组中的位置-是储存在隐藏类的哈希表中。同一隐藏类的对象具有相同的属性名称。如果知道对象类,那么就可以利用位移依数组操作存取属性。这比搜寻哈希表快许多。
然而,在JavaScript等动态语言中,很难事先知道对象类型。例如,图8的原始码为对象类型p和q呼叫lengthSquared()函数。对象类型p和q的属性不同,隐藏类也不同。因此无法判定lengthSquared()函数代码的参数(arguments)类型。
若要读取函数中的对象属性,必须先检查对象的隐藏类,并有搜寻类的哈希表,以找出该属性的位移。然后利用位移存取数组。尽管是在数组中存取属性,要先搜寻哈希表的需求就毁掉了使用数组的优点。
然而,从不同的观点来看,情况有所不同。在实际的程序中,依赖代码执行判断类型的情况并不多。例如,在图8的lengthSquared()函数甚至假设大部分通过成为参数的值,都是Point类对象,而一般而言这是正确的。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
function lengthSquared(p) { return p.x* p.x+ p.y* p.y; } function LabeledLocation(name, x, y) { this.name= name; this.x= x; this.y= y; } var p= new Point(10, 20); var q= new LabeledLocation("hello", 10, 20); var plen= lengthSquared(p); var qlen= lengthSquared(q); |
图8 代码样本:JavaScript无法判断函数参数类型
在执行之前根本无法判断参数是Point型或是lengthSquared()函数的LabeledLocation型。
内嵌缓存是一项加速技术,此设计是为了利用程序中局部(local)类别的方法。若要程序化的属性存取,V8会产生一个指令串来搜寻隐藏类列表(图9)。此代码称为premonomorphic stub。此stub是为了在函数存取属性(图10)。Premonomorphic stub拥有两个信息:搜寻用的隐藏类,以及取自隐藏的位移。最后会产生新代码以缓存此信息(图11)。
|
1 2 3 4 5 6 |
Object* find_x_for_p_premorphic(Object* p) { Class* klass= p->get_class(); int offset = klass->lookup_offset("x"); update_cache(klass, offset); return p->properties[offset]; } |
图9 在伪代码(pseudocode)中的premonomorphic stub 从隐藏类中取得属性位移。
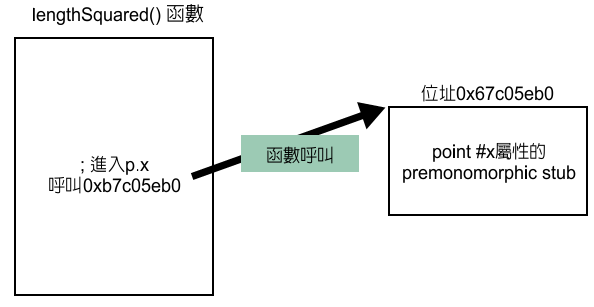
图10 premonomorphic stub呼叫存取函数中的属性时会呼叫premonomorphic stub。
|
1 2 3 4 5 6 7 |
Object* find_x_for_p_monomorphic(Object* p) { if (CACHED_KLASS == p->get_class()) { return p->properties[CACHED_OFFSET]; } else { return lookup_property_on_monomorphic(p, "x"); } } |
图11伪代码的monomorphic stub 处理直接嵌入代码中的位移是用来存取属性的常数。
在搜寻表格之前,带有属性的对象之隐藏类会与缓存隐藏类比较。如果相符就不需要再搜寻,且可以使用缓存的位移来存取属性。如果隐藏类不相符,就透过隐藏类哈希表以一般方式判断位移。
新产生的代码被称为monomorphic stub。「内嵌」这个字的意思是查询隐藏类所需的位移,是以立即可用的形式嵌入在所产生的代码中。当第一次叫出monomorphic stub时,它会将功能从pre-monomorphic stub位址中所叫出的第一个位址重写成monomorphic stub位址(图12)。自此,使用高速的monomorphic stub,单靠类比较和数组存取就可以处理属性存取。
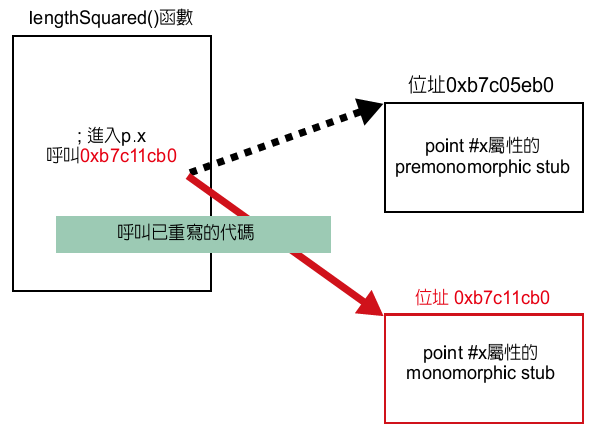
图 12 monomorphic stub呼叫
当呼叫monomorphic stub时,它会将功能从premonomorphic stub位址中叫出的第一个位址,重写成monomorphic stub位址。
如果只有一个具有属性的对象,monomorphic stub的效率就会很高。然而,如果类型愈多,缓存失误就会更频繁,进而降低monomorphic stub的效率。
当缓存失误时,V8藉由产生另一个称为megamorphic stub的代码来解决(图13)。与个别类对应的monomorphic stub都写在哈希表中,其在执行时搜寻和叫出stub。如果没有类型对应的monomorphic stub时,就会从类型哈希表中搜寻位移。
|
1 2 3 4 5 6 7 8 9 10 11 |
Object* find_x_for_p_megamorphic(Object* p) { Class* klass= p->get_class(); //内嵌处理实际的搜寻 Stub* stub= klass->lookup_cached_stub("x") if (NULL != stub) { return (*stub)(p); } else { return lookup_property_on_megamorphic(p, "x"); } } |
图13伪代码中的Megamorphic stub处理与类型对应的monomorphic stub事先储存在哈希表中,并在执行时被搜寻和叫出。如果无法找到对应的monomorphic stub,就会在类型哈希表中搜寻位移。
当monomorphic stub发生缓存失误时,monomorphic stub会将功能从monomorphic stub位址叫出的第一个位址以megamorphic stub位址重写。在代码搜寻方面,megamorphic stub的性能比monomorphic stub低,但是megamorphic代码却比使用缓存更新、代码生成及其他辅助处理的premonomorphic stubs快许多。
涵盖多种类的内嵌缓存称为多型态内嵌缓存(polymorphic inline cache)。V8内嵌缓存系统被用来呼叫方法以及存取属性。
机器语言的特性
如以上所述,V8在设计时使用了例如内嵌缓存等,来达到动态语言中天生的速度。创建使用于内嵌缓存之stub的机器语言生成模块密切地与JIT编译器连结。
一些经常使用的方法也被写成机器语言以达到与内嵌拓展相同的效果,使它们成为「内在」的。V8原始码列出了内在转换的候选名单。
V8所含的shell程序可以用来检查V8所产生的机器语言。所产生的指令串可以和V8代码比较,以便显出它的特性。
例如,在执行图14a所示的JavaScript函数时,就会产生一个如图14b所示的x86机器语言指令串。此函数在第39个指令中被呼叫,是个「n+one」加法。在JavaScript中,「+」操作数指示数字变量的加法,以及字符串的连续性。编译器不是产生代码来判决这是哪一种,而是呼叫函数来负责判断。

图14 V8从JavaScript代码产生的机器语言加法处理被转换成函数呼叫的机器语言(a、b)
如果图14的函数稍做更改(图15),那图14b的函数呼叫就会消失,但会有个加法指令(第20),及分支指令(JNZ的若不是零就跳出,第31)。当使用整数作为「+」操作数的操作数,V8编译器在不呼叫函数下会产生一个有「加法」指令的指令串。如果发现操作数(在此为「n」)成了Number对象或String对象等的指标(pointer),
就会叫出函数。「加法」只会发生在当两个「+」运算的操作数都是整数时。在这种情况下,因为可以跳过函数呼叫所以执行就会比较快。

图15 V8从图14之JavaScript中所产生的机器语言,经小幅修改
此外,0x2会加上「加法」指令,因为为最低有效位(least significant bit, LSB)被用来区别整数(0)和指标(1)。加0x2(二进制中的十)就如同在该值加上1,LSB除外。在jo指令的溢位(overflow)处理中,利用测试和jnz指令来判定指标,跳到下游处理(注1)。
这类的窍门在编译器中到处都有。然而,产生器代码也透露了编译器的限制。具传统最佳化的编译器可以针对图14和15产生完全一样的机器语言,这是由于常数进位的关系。然而V8编译器是在抽象语法树*(abstract syntax tree)单元中产生代码,因此在处理延伸多个节点时就没有最佳化。这在大量的push和pop指令也非常明显。
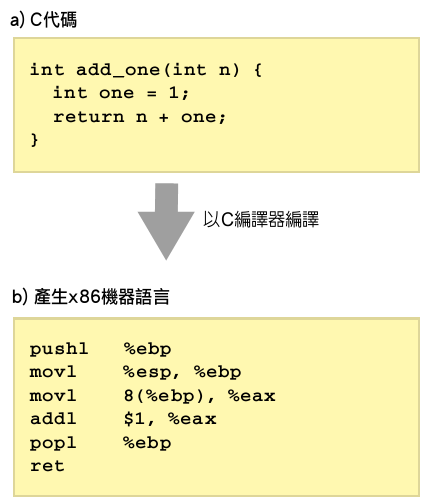
图16显示了C语言里相同的处理提供参考。由于C和JavaScript之间的语言规范不同,因此所产生的机器语言是图14和图15的不同,这和编译器的性能无关。
图16 C编译器从C代码所产生的机器语言所产生的机器语言比V8所产生的干净许多(a、b),大部分是因为C和JavaScript语言规范的差异所致。
注1:当溢位信号出现时,jo指令会跳至特定的位址。测试指令将逻辑AND结果反映成零和符号指标等。除非零信号出现,否则jnz指令会跳至特定的位址。
* Abstract syntax tree抽象语法树:在树状架构中代表程序架构的数据。
附录:熟悉OOP的程序员之参考
JavaScript没有类,但为了让熟悉使用类(面向对象的代码)之程序员更方便使用,可以使用「new」的操作数来建立对象,就像在Java一样。在「new」操作数之后会定义一个特别的「constructor」建构函数(图B-1 a, b)。
然而,即使没有建构函数,也可以建立对象(图B-1c)和设定属性的(图B-1 d)。JavaScript对象的属性和法等随时都可以新增或删除。
除了用点标记(dot notation)存取JavaScript属性以外,也可以使用括号,建议散列(hashing)存取(图B-1 e、f)或是以变量特定属性名称字符串(图B-1 g)。从这些范例中明确显示JavaScript对象的设计是为了使用哈希表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
a) 定义建构函数「Point」 function Point(x, y) { // this是指它自己 this.x= x; this.y= y; } b) 当增加新的及呼叫建构器函数时所建立的对象 var p= new Point(10, 20); c) 没有建构器函数也可以建立对象 var p= { x: 10, y: 20 }; d) 可以自由地在对象上新增属性 p.z= 30; e) 使用点标记存取属性 var y= p.y f) 使用括号之散列(hashing)存取 var y= p["y"]; g) 也可以使用变量进行散列(hashing)存取 var name= "y"; var p[name]; |
本文虽然写于2009年V8刚刚推出的时候,其中仍对理解V8有很大帮助。
原文地址:http://techon.nikkeibp.co.jp/article/HONSHI/20090106/163615/
繁体中文版地址: http://www.greenpublishers.com/neat/200901/3coverstory.pdf
*本文是以繁体中文版为基础重新修订的。看起来繁体中文版本多为机翻后人工校正的,除去两岸的专业词汇不同外,仍有不少不通的地方。最明显的就是将class翻译为层级。
转载自:求索




很好啊.谢谢博主啊
旁边的目录好漂亮
越来越漂亮咯 支持一个
who 太眼熟的id
太眼熟的id